Google Dropped 470 of Our Pages in One Weekend. AI Search Cites Us 31,000 Times.
One hundred days of building a new publication in the AI-search era, told through its own analytics: the fastest index growth we could have asked for, a three-day ejection during the May core update, and the strange fact that the only thing the human web has linked to is the file we wrote for machines. All the numbers below are from our own exports, and we will publish the follow-up whichever way it goes.
The numbers, as of 30 June 2026
- Site age: roughly 100 days. 868 live URLs, of which 267 are editorial pages.
- Google index: 87 pages on 6 April → 605 on 26 May → 100 from 13 June onwards.
- Google impressions: ~300 per day in April, 694 per day in the peak week (25–31 May), under 10 per day since mid-June — a fall of roughly 99%.
- “Crawled – currently not indexed”: 592 URLs, including 24 of our 25 most AI-cited pages.
- 31,085 citations in AI-generated answers across 267 pages and 576 distinct grounding queries, per Bing Webmaster Tools’ AI reports.
- Citation share on our strongest topic cluster: 50–70% of AI answers to benchmark-style questions.
- Bing organic: every sampled URL returns HTTP 200; 3,957 impressions and 180 clicks in the period, still growing.
- External backlinks found by Bing: seven — all pointing at our llms.txt page. None to any content page.
What this site is, and how it is made
Uncompromised Travel is an independent luxury-travel publication — private aviation, yacht charter, expeditions, stays, travel intelligence, relocation — run by one person from Valencia, Spain, funded by affiliate commissions, with no advertising. In the interest of the case study being worth anything: pages are produced with AI assistance under a fixed human editorial specification — canonical templates, a mechanical pre-publish verification gate, a named-source outbound-linking policy — at a pace that reached ten pages a day. That pace is part of this story, and not flatteringly.
Eight weeks of the best growth chart we will ever delete
Google discovered the site quickly and indexed it steadily: 87 pages in the index on 6 April, 190 by late April, 377 by 19 May, 605 by 26 May. Impressions compounded in parallel, from roughly 300 a day in April to a peak week averaging 694 a day. By any standard for a brand-new domain, this was working — Google read the pages, kept them, and served them in growing volume for eight weeks.
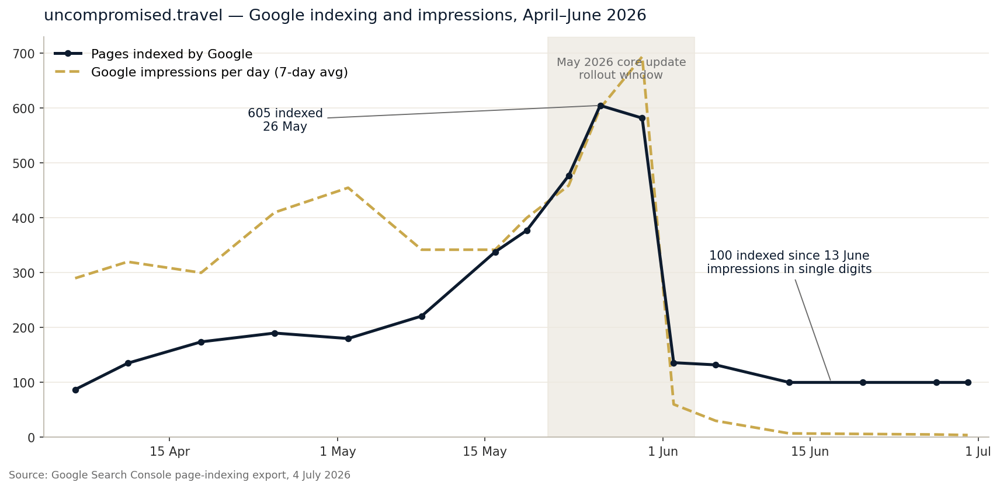
Indexed pages and daily impressions, April–June 2026. Source: Google Search Console.
Then the weekend of 30 May
Between 30 May and 2 June the indexed count fell from 582 to 136. Three days. By 13 June it settled at exactly 100 pages, where it has sat, unmoving, ever since. Impressions fell to single digits and stayed there.
The dates matter. Google’s May core update began rolling out on 21 May and completed in early June. Our ejection landed in its closing days. There was no manual action, no security issue, no message — only Search Console’s politely grey label against 592 URLs: Crawled – currently not indexed. That bucket is not a penalty; it is Google’s quality-selection queue — pages it has fetched, evaluated, and declined to store.
What Google’s own reports say
The detail that reframed everything: it is not our thin pages in that refused list — it is our flagships. Twenty-four of the twenty-five pages that AI engines cite most are excluded from Google’s index, including the Luxury Safari Operator Index (4,968 AI citations) and our EU261 claim-service comparison (6,293). Pages carrying roughly 70% of all our AI citations are pages Google has inspected and declined to keep. And Googlebot has not lost interest — crawl dates on the refused pages run right up to the present. It re-reads them. It just does not store them.
Meanwhile, the other machines
Bing Webmaster Tools now reports AI citations, with the underlying grounding queries and per-page attribution — a report many site owners do not know exists. It attributes 31,085 citations to this site across 576 distinct queries in the period. On our strongest cluster we appear in half to two-thirds of AI answers to benchmark-style questions. In analytics, ChatGPT is our largest identifiable human referrer, and a large share of “direct” traffic behaves like unattributed AI referral. Bing’s conventional index, for its part, crawls the same pages cleanly — every URL in its Site Explorer sample returns 200 — ranks them, and sends a small but growing stream of clicks.
Two sets of machines read the same 267 pages and reached opposite verdicts.
The one number that explains the gap
Bing’s link data for the entire site: seven backlinks, all seven pointing at /llms — the llms.txt manifest we publish for AI crawlers. Not one content page has a single external link. Directories of AI-readable sites found the machine manifest before any human publisher found the content.
And there is the diagnosis. For a new domain, modern Google’s admission decision is not a content judgement; it is a trust judgement, and trust is computed from what the rest of the web says about you. The rest of the web currently says nothing about us — except to other machines.
What we think happened — and what we don’t
We do not think this is AI-content detection. Bing indexes the same pages; AI engines cite them thousands of times a week; and Google’s published spam policies target scale and intent, not tooling.
We think the domain matched a pattern the May core update was tuned to remove: under 100 days old, 868 templated URLs published at ten a day, effectively zero earned links, affiliate-funded. Google’s policies call that pattern scaled content abuse. A classifier cannot interview you about editorial intent; it reads velocity, age, structure and external trust — and every one of those signals, on this domain, said the same thing. We built, in good faith, the statistical profile of the thing the update was built to catch. The update did not evaluate our pages — it had already read them, indexed them and ranked them for eight weeks. It re-evaluated our domain, in a weekend.
What we got wrong
Treating publishing velocity as an asset — at domain level it is now a liability, because the site-wide average is what gets scored and every fast page lowered ours. Treating indexing as a finish line rather than a lease. Building all of our trust signals on-site when the admission decision is made off-site. And a small one of a piece with the rest: our sitemap stamps an identical lastmod on every URL at generation time, which tells Google, several hundred times a day, that our freshness signal lies.
What we are doing about it — in public
Publishing is cut to one or two genuinely deep pages a day. The long tail is being pruned and merged. We are earning references the slow way: pitching our proprietary indexes as citable data, answering journalist requests, and beginning quarterly publication of original price data of the kind luxury travel prefers to keep opaque. Google’s own recovery guidance amounts to: improve, and wait for a future update to notice. So we will report back in about ninety days with these same charts, whichever direction they point. If the indexed line is still flat at 100, you will see that too.
Data and method notes
Sources: Google Search Console page-indexing exports (4 July 2026) and performance chart (5 April–30 June); Bing Webmaster Tools Site Explorer, search performance and AI reports (exports 30 June–4 July); GA4 (22 March–30 June). Caveats: Bing’s backlink data is sampled, not exhaustive; GA4 undercounts due to blockers; AI-citation counting follows Bing’s attribution methodology; a share of “direct” traffic is unattributable by nature. The underlying exports are available to anyone reporting on this — contact us.
— Richard
Uncompromised Travel